Home
![]()


![]()
![]()
Quicksql is a SQL query product which can be used for specific datastore queries or multiple datastores correlated queries. It supports relational databases, non-relational databases and even datastore which does not support SQL (such as Elasticsearch, Druid) . In addition, a SQL query can join or union data from multiple datastores in Quicksql. For example, you can perform unified SQL query on one situation that a part of data stored on Elasticsearch, but the other part of data stored on Hive. The most important is that QSQL is not dependent on any intermediate compute engine, users only need to focus on data and unified SQL grammar to finished statistics and analysis.
Architecture¶
An architecture diagram helps you access Quicksql more easily.
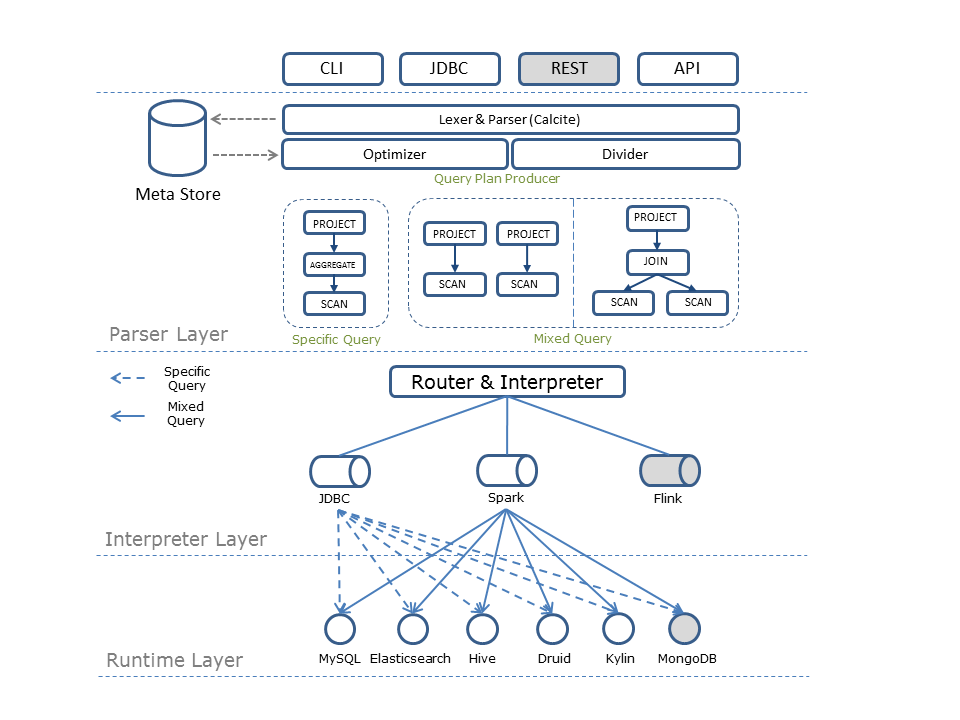
QSQL architecture consists of three layers:
-
Parsing Layer: Used for parsing, validation, optimization of SQL statements, splitting of mixed SQL and finally generating Query Plan;
-
Computing Layer: For routing query plan to a specific execution plan, then interpreted to executable code for given storage or engine(such as Elasticsearch JSON query or Hive HQL);
-
Storage Layer: For data prepared extraction and storage;
Basic Features¶
In the vast majority of cases, we expect to use a language for data analysis and don't want to consider things that are not related to data analysis, Quicksql is born for this.
The goal of Quicksql is to provide three functions:
1. Unify all structured data queries into a SQL grammar
- Only Use SQL
In Quicksql, you can query Elasticsearch like this:
SELECT state, pop FROM geo_mapping WHERE state = 'CA' ORDER BY state
Even an aggregation query:
SELECT approx_count_distinct(city), state FROM geo_mapping GROUP BY state LIMIT 10
You won't be annoyed again because the brackets in the JSON query can't match ;)
- Eliminate Dialects
In the past, the same semantic statement needs to be converted to a dialect for different engines, such as:
SELECT * FROM geo_mapping -- MySQL Dialect
LIMIT 10 OFFSET 10
SELECT * FROM geo_mapping -- Oracle Dialect
OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY
In Quicksql, relational databases no longer have the concept of dialects. You can use the grammar of Quicksql to query any engine, just like this:
SELECT * FROM geo_mapping LIMIT 10 OFFSET 10 -- Run Anywhere
2. Shield the isolation between different data sources
Consider a situation where you want to join tables that are in different engines or are not in the same cluster, you may be in trouble.
However, in Quicksql, you can query like this:
SELECT * FROM
(SELECT * FROM es_raw.profile AS profile //index.tpye on Elasticsearch
WHERE note IS NOT NULL )AS es_profile
INNER JOIN
(SELECT * FROM hive_db.employee AS emp //database.table on Hive
INNER JOIN hive_db.action AS act //database.table on Hive
ON emp.name = act.name) AS tmp
ON es_profile.prefer = tmp.prefer
3. Choose the most appropriate way to execute the query
A query involving multiple engines can be executed in a variety of ways. Quicksql wants to combine the advantages of each engine to find the most appropriate one.
Getting Started¶
For instructions on building Quicksql from source, see Getting Started.
Reporting Issues¶
If you find any bugs or have any better suggestions, please file a GitHub issue.
And if the issue is approved, a label [QSQL-ID] will be added before the issue description by committer so that it can correspond to commit. Such as:
[QSQL-1002]: Views generated after splitting logical plan are redundant.
Contributing¶
We welcome contributions.
If you are interested in Quicksql, you can download the source code from GitHub and execute the following maven command at the project root directory:
mvn -DskipTests clean package
If you are planning to make a large contribution, talk to us first! It helps to agree on the general approach. Log a Issures on GitHub for your proposed feature.
Fork the GitHub repository, and create a branch for your feature.
Develop your feature and test cases, and make sure that mvn install succeeds. (Run extra tests if your change warrants it.)
Commit your change to your branch.
If your change had multiple commits, use git rebase -i master to squash them into a single commit, and to bring your code up to date with the latest on the main line.
Then push your commit(s) to GitHub, and create a pull request from your branch to the QSQL master branch. Update the JIRA case to reference your pull request, and a committer will review your changes.
The pull request may need to be updated (after its submission) for two main reasons:
- you identified a problem after the submission of the pull request;
- the reviewer requested further changes;
In order to update the pull request, you need to commit the changes in your branch and then push the commit(s) to GitHub. You are encouraged to use regular (non-rebased) commits on top of previously existing ones.
Join us¶


